Experiment
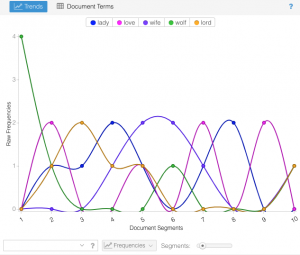
Text mining of the most relevant blogs and websites about Spanish “Indignados” movement using Voyant-Tools.
Selection criterion: Official websites of the movement compiled in https://movimientoindignadosspanishrevolution.wordpress.com/paginas-web-oficiales-del-15m-en-espana/
Official means, in this case, the websites that came directly from the organization (squares and other spontaneous places for meetings)
Defining a corpus is not easy; that’s why it is useful to build upon a previously made selection.
Purpose of the experiment: Search for the most common buzzwords or theoretical concepts related to the movement and gathered in its blogs and websites. They will be extracted from the list of terms within the first 250. Words that are not relevant for the experiment (as verbs; prepositions; or names of people, places, months or days) will not be taken into account.
Limitations
First of all, it should be pointed out that some of the websites and blogs are not active anymore (perhaps they can be retrieved using internet archive). Moreover, some of the domains belong now to other business or even to other countries. Last but not least, other sites are blocked because of their political content (especially in the U.S.).
Voyant-Tools proves unable to move all the corpus (perhaps due to the abovementioned limitations). Then I decided to conduct the experiment splitting the corpus in chunks. That option did not work either; so, I opted for extracting the malfunctioning links from the corpus. It rendered the same error. Finally, facing the impossibility of analyzing a comprehensive corpus, I took the decision to include only 20 websites, which would represent some of the biggest cities of Spain. After doing that, I was able to visualize the data.
Interpreting the results
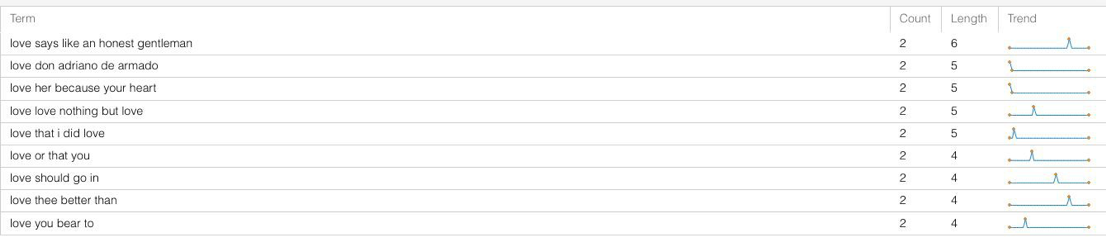
Some of the most abundant concepts were Assembly, Consensus, Commission, Share, Proposal(s), Camp, Twitter, Facebook, Minutes, and Plaza. Other buzzwords in the list of the 100 more used were Evictions, 15m, Compañeros, Demonstration, Repression…

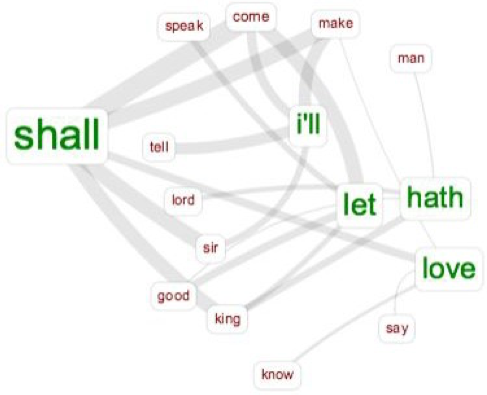
When the link map is displayed the results that are shown are by no means contradictory. It seems obvious that Assembly is connected to General, Commissions and Inter. Likewise, it comes as no surprise that Share is associated with Facebook, Twitter, Blog, and Pinterest.
Looking at the bubble lines, one can unfortunately realize that the outputs are manly concentrated in a few websites (Bilbao, Soria, Salamanca, Gudadalajara, and Vigo); most probably as a result of being more text mining friendly. That could simply have occurred because of presenting more text in their home tab.

One of the unusual findings is that Share is the most used concept (98 times) followed by Assembly (56 times). Thus, one can conclude that text mining tools applied to social movements’ archives help discover largely used words which give account of concepts that shape collective political subjectivities and that are propably unnoticed. For instance, quantitave analysis shows that Share not only has a practical use, connected to the idea of spreading the word through social media, it also portrays the idea of a sharing community.
It is clear that for a proper analysis, the selection and preparation of the corpus is fundamental. The rendering of the data is affected by minimal changes on the corpus. Perhanps my modest experiment with Voyant cannot serve the purpose of generalizing assumptions. In this respect, the relationship between signals and concepts was not fully developed and appeared as weak in my case study. However, signals such as Consensus, Assembly, Share, Proposal or Plaza configured a linguistic map around certain concepts that are definitely related to the new political subjectivity of the “Indignados” movement. Some of them were evident, other surprising, and many remain undiscover, waiting for future reserarches.

 Zohra Saed on
Zohra Saed on